自从NV开放 4GB版本的GTX680之后,所有游戏都阻止不了GTX680了。除了游戏,我们还有什么点子可以发挥这块单芯片神卡的威力呢?没错,就是通用运算技术CUDA!高性能运算,复杂的物理运算和人工智能仿真等等的如果只用CPU运行,估计6核的Ivy Bridge也够呛的了。即使启动了超线程技术,也只能硬件上实现12线程。对于动辄上千ALU的GPU来说,这只能是小菜一碟。另外,还有一个巨大的线程切换差异,就是说CPU多线程切换需要上千时钟周期,而GPU则只需要个位数的时钟周期。
这就为什么GPU隐藏着巨大的能量。NVIDIA很聪明地看到了这块市场的契机。Fermi的设计首创性地加入了和处理器一样的统一读写二级缓存,随后GK104更把底层的SMX进行变革。下面我们通过技术宅男玩家为我们展开一场奇幻的CUDA旅行。当然,主角是当下性能极其强悍的GTX680 4GB。

据说,技术宅的厕纸用完了之后就会用书本。

技术宅受到刺激后,迷上了超大规模程序设计,那个叫什么CUDA神秘兮兮的东西。

平台艳照

那个神秘兮兮的CUDA的环境配置。1安装CUDA工具箱,第二步安装显卡驱动,第三步安装CUDA SDK。前两步必不可少,第三步可以缺省。
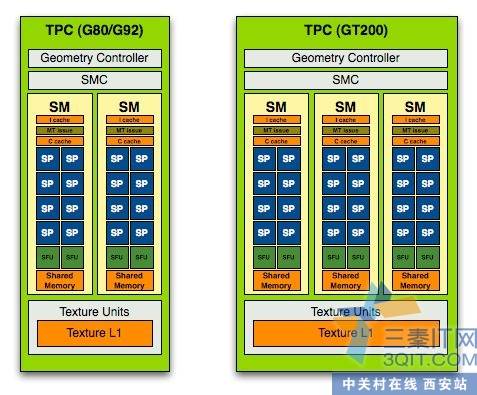
技术宅帮我们复习一下,G80和GT200的SM架构。这种差异导致了CUDA程序上的不同优化。
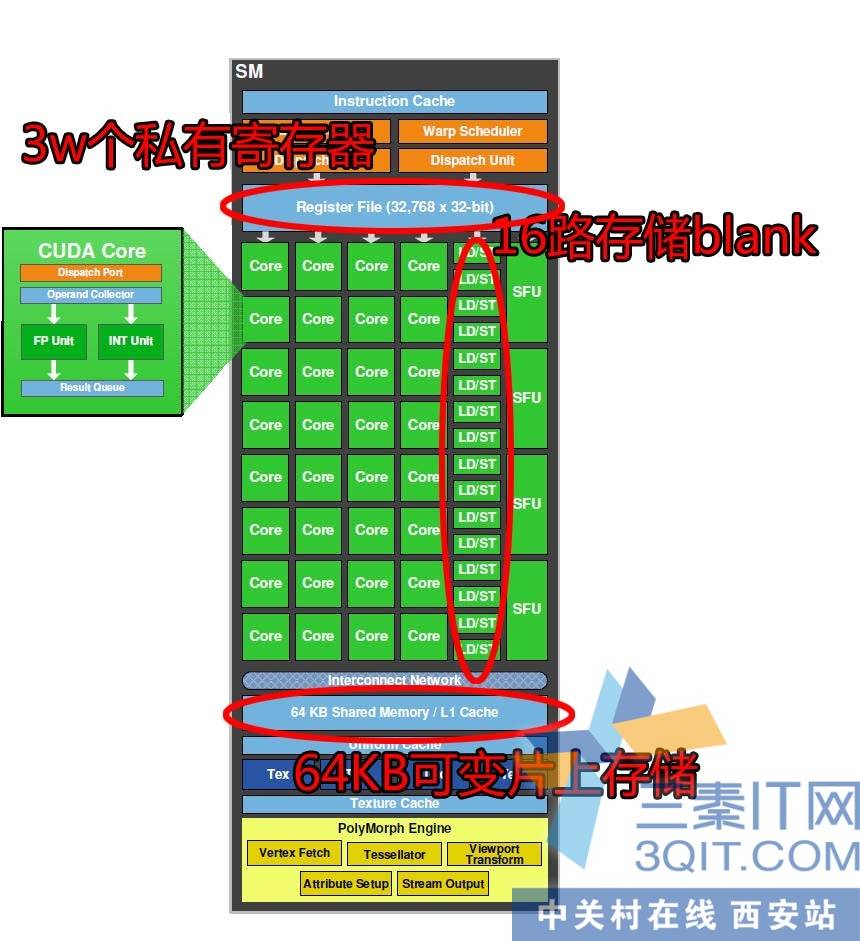
好了,老架构的不花时间去讨论,直奔最近在通用计算大放异彩的费米架构。技术宅说它革命性地加入了读写统一的1,2级缓存。亲,这是模仿CPU的设计吗?下面结合硬件来说说CUDA是如何根据它来优化。SM拥有3万个高速寄存器!天哪,8核CPU的不过百的寄存器情何以堪!难怪线程切换的速度如此之快。16路高速存储通道来并行操作64KB的片上高速缓存,速度达到1TB/s的级别!!!!!!
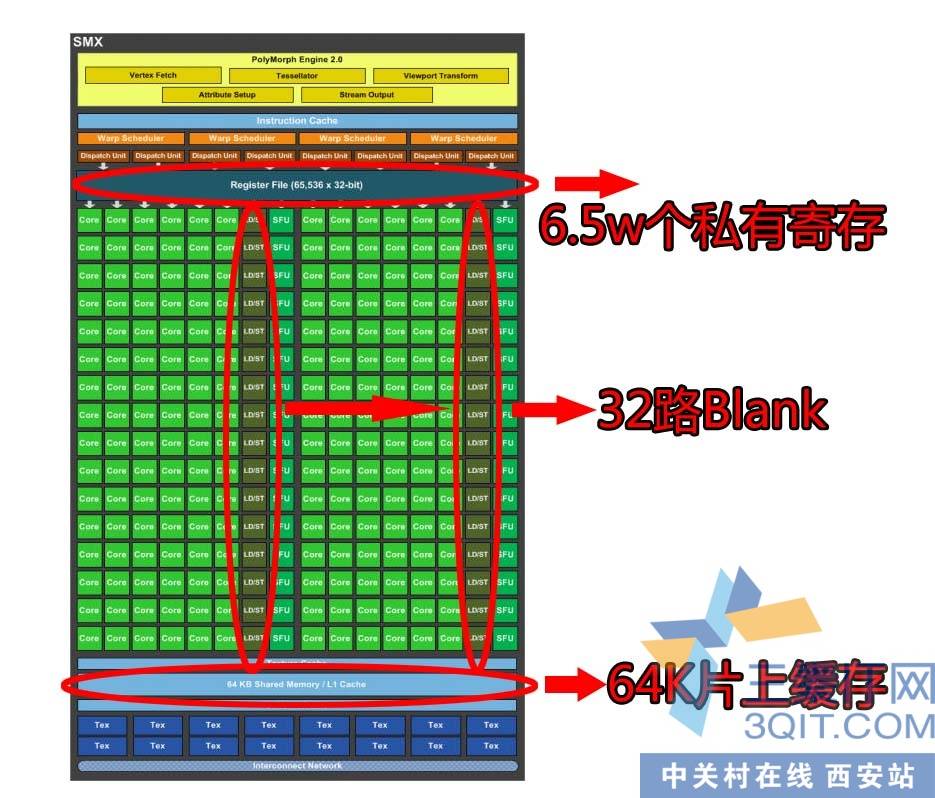
开普勒再度加强,在晶体管数量控制在30亿的情况下竟然设计出比费米多100%的CUDA核心。从SMX架构上可以到处,要以往 CUDA程序为开普勒优化,首要任务是让block里面的线程尽量地多。GT200 SM允许活动线程是1024个,费米优化的代码可以增加到1536个线程,而开普勒更爆增到2048个活动线程(注:规格上和GK110一样)。
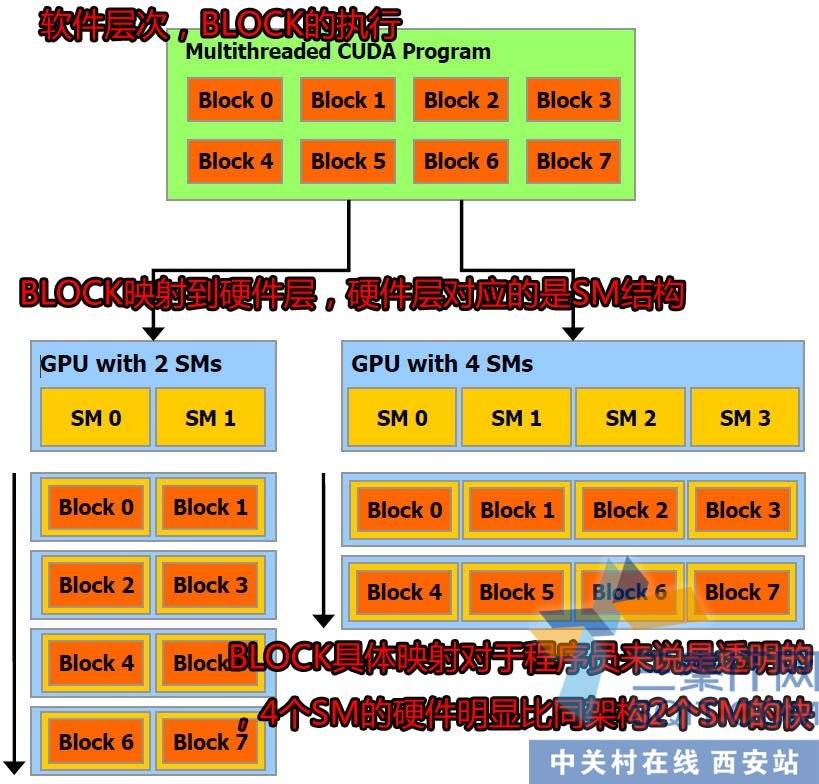
这个是软件层次对应的硬件层次。BLOCK编程上的线程块,它们是分时在SM里运行,一个CUDA程序会有多个blcok并行运行,而每个block就是说线程块又包含了舒数十到上百的线程组成。也就构成了CUDA。
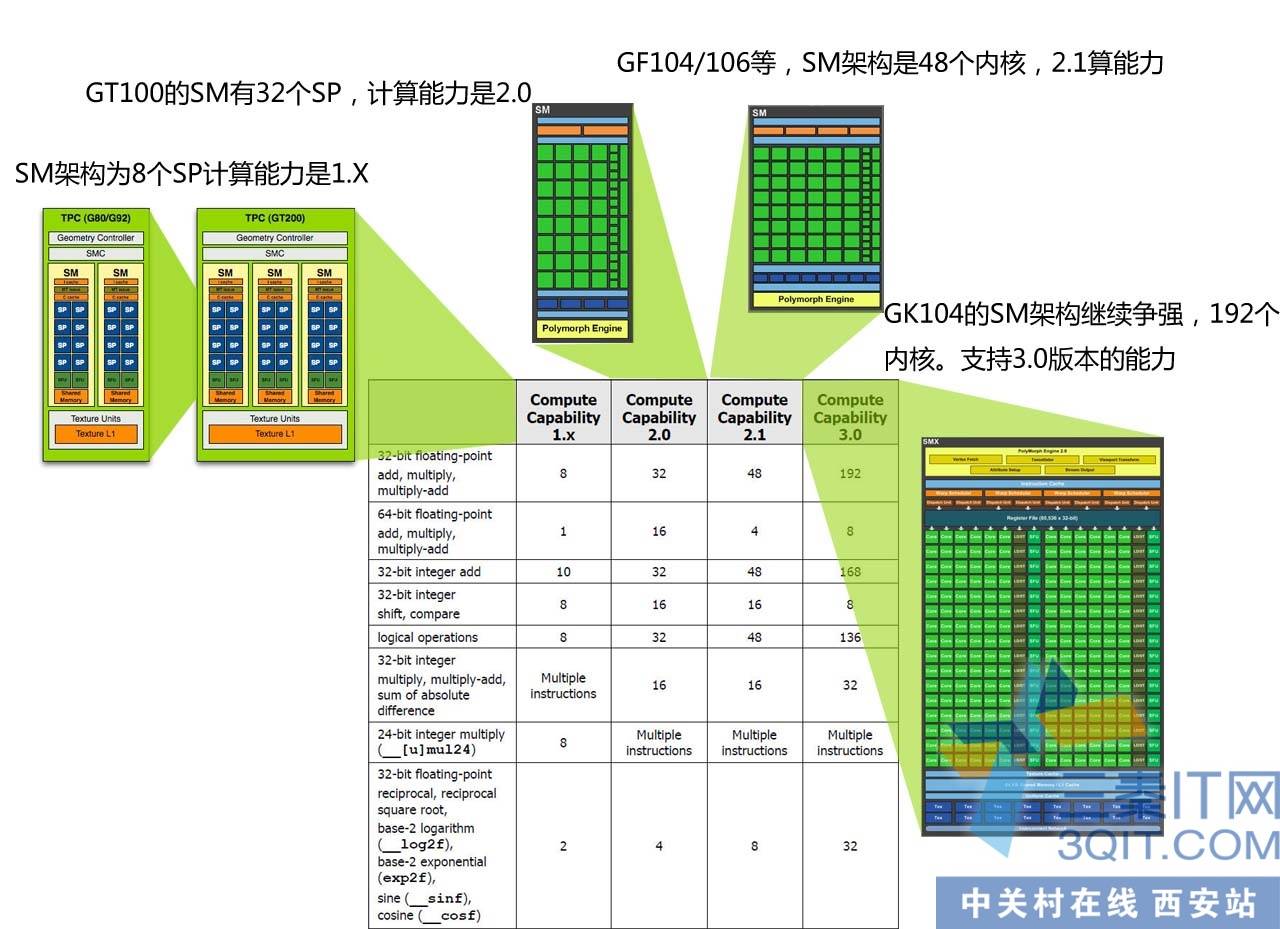
架构的不同对应不同的计算规格。3代运算架构,对用不同的支持。代码优化可以适当对不同特征进行优化。譬如开普勒等硬件可以支持更大的block内部线程,因此可以支持更多的线程进行片上的同步工作。另外譬如Fermi和开普勒有DRAM缓存,所以对DRAM优化的力度没有G80那么吃力。
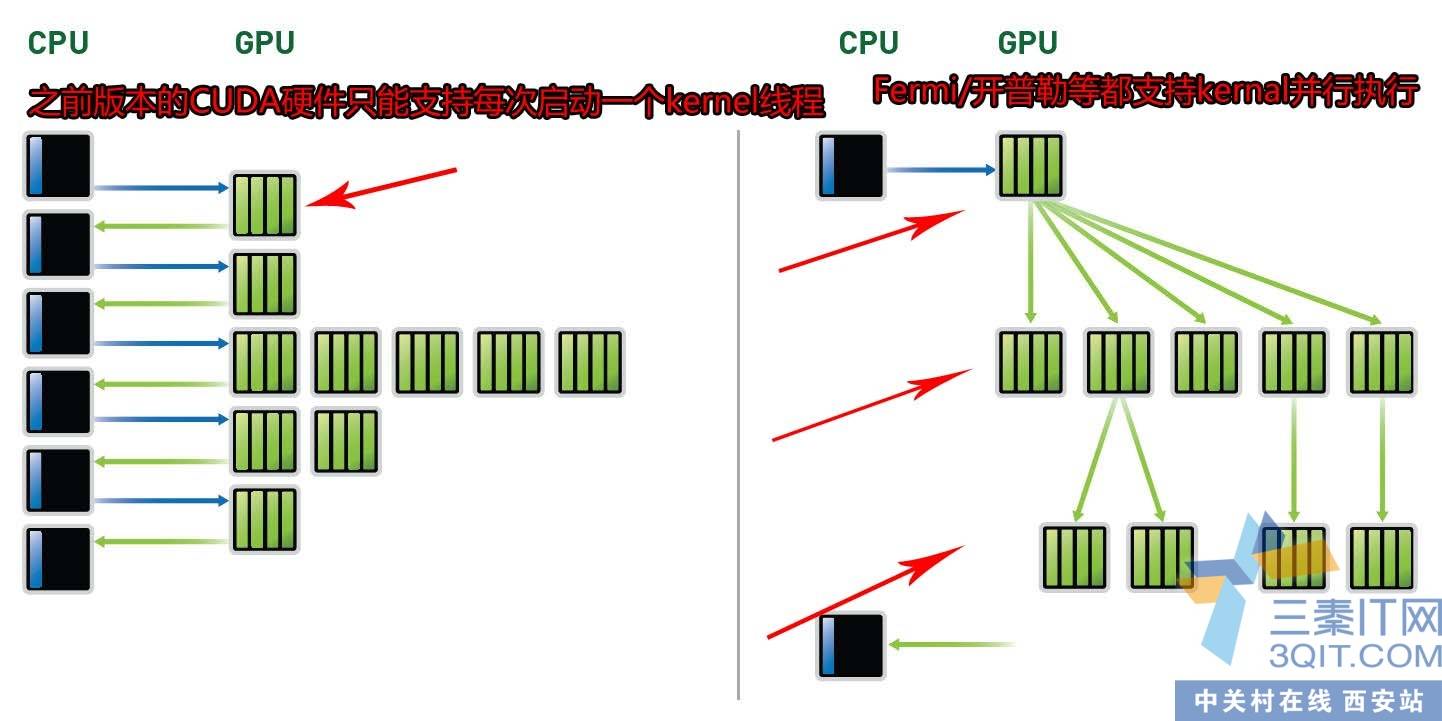
开普勒在CUDA上加入了更大的革新。就是支持多内核函数的并行执行。注意一个CUDA内核就是一个可具备百万线程的并行程序,而这些内核函数更可以并行执行。
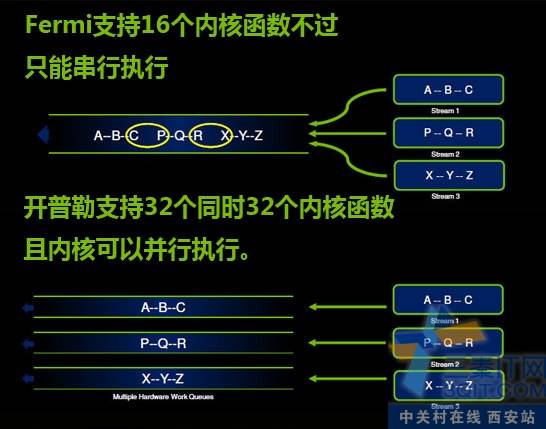
开普勒在内核函数执行引擎上比费米有了更大的加强。
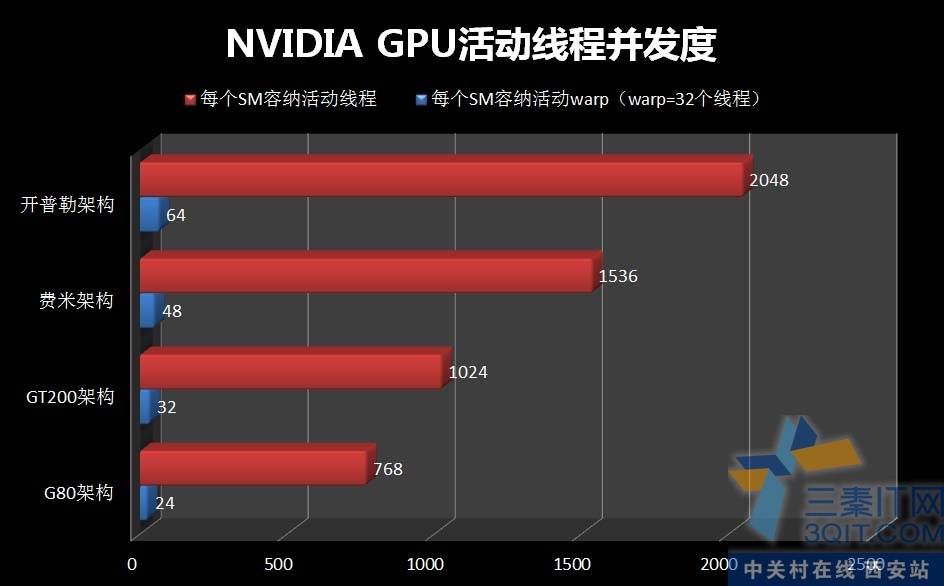
从CUDA的发展角度看,NVIDIA一共经历了4代CUDA架构的更新。不过,唯一不变的是warp硬件指令的宽度。(这里和AMD的稍微不同,AMD的硬件指令宽度是64)。
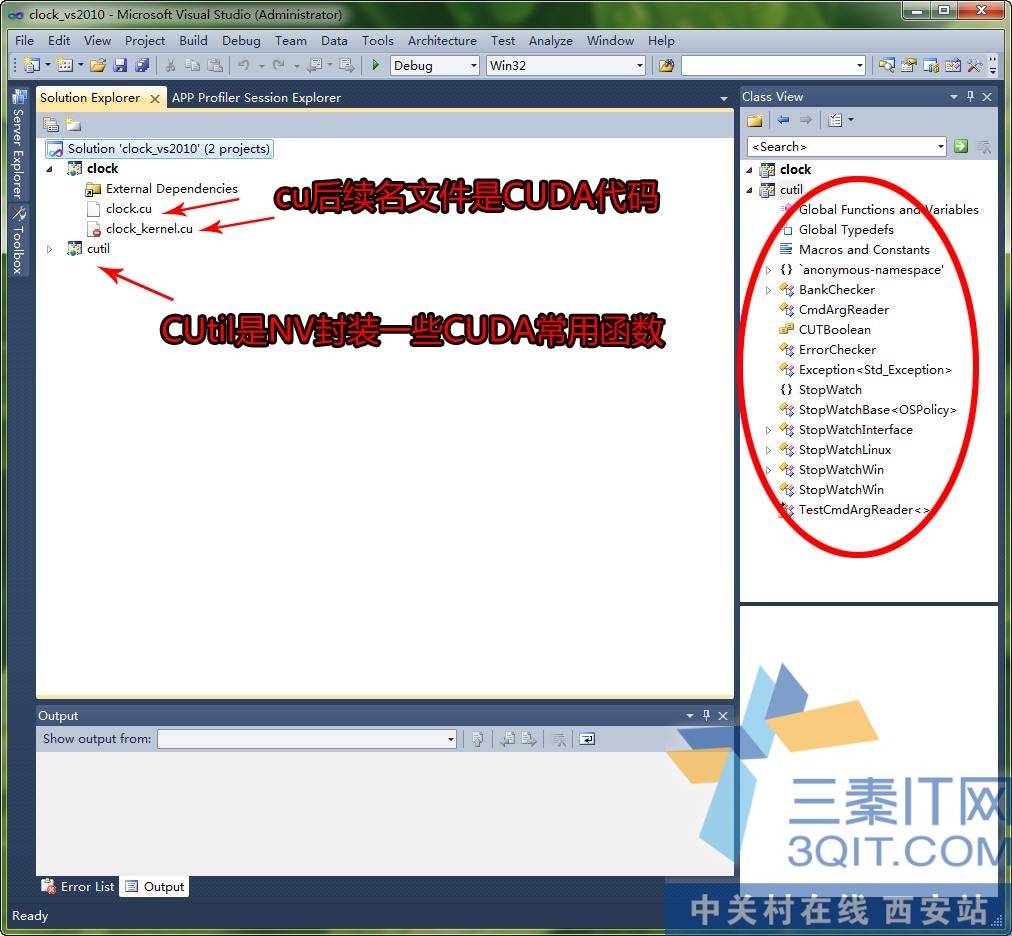
想要CUDA编程的童鞋可以开始了。安装好驱动,工具箱后,就可以安装C/C++编辑器了。用微软的VS比较方便,本人安装的是VS2010。另外VS本身是不支持CUDA语法,可以在工具箱里面找语法配置文件,在VS里配置一下就可以了。好了, 打开神秘的CUDA代码,其实CUDA代码是C和一些C的扩展而已,懂C的朋友很容易就明白了。CUDA文件以CU后续,CUDA代码的编译成系统执行文件有点小小麻烦。因为需要调用到2个编译器,一个是C/C++,另外一个是GPU编译器。不过NVDIA提供了NVCC工具比较方便,NVCC是一个半编译和连接的工具,它主要是分离CPU和GPU代码,然后把CPU代码给VS2010编译,再者自己编译GPU代码。编译后连接好就可以编程执行代文件了。
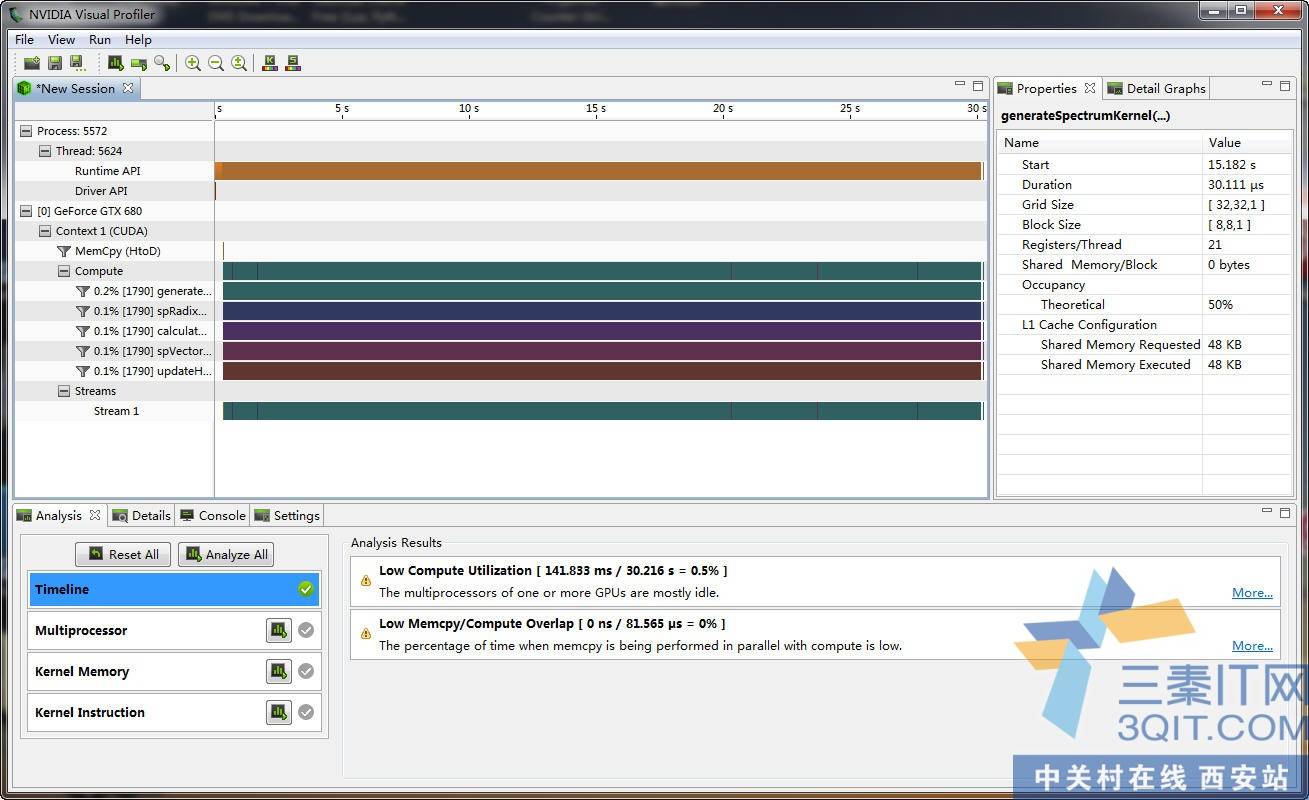
这是NV的性能调试工具,这个工具非常不错,可以可视化分析到硬件的使用率。
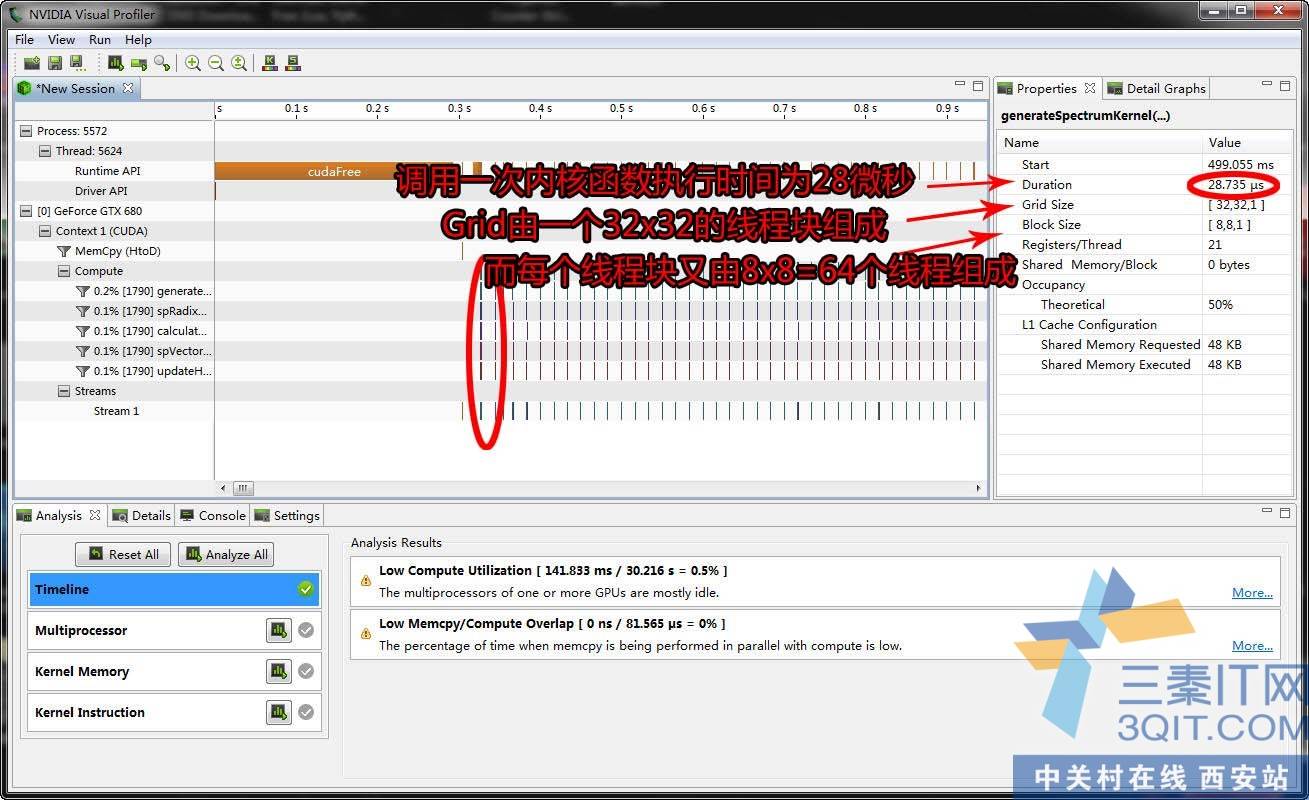
程序的产生都可以清楚分析,这是一个CUDA二维傅立叶变换的例子。不过计算单元的使用率不高,虽然很密集地运行kernel,不过每个kernel的执行时间不长。20多微秒。
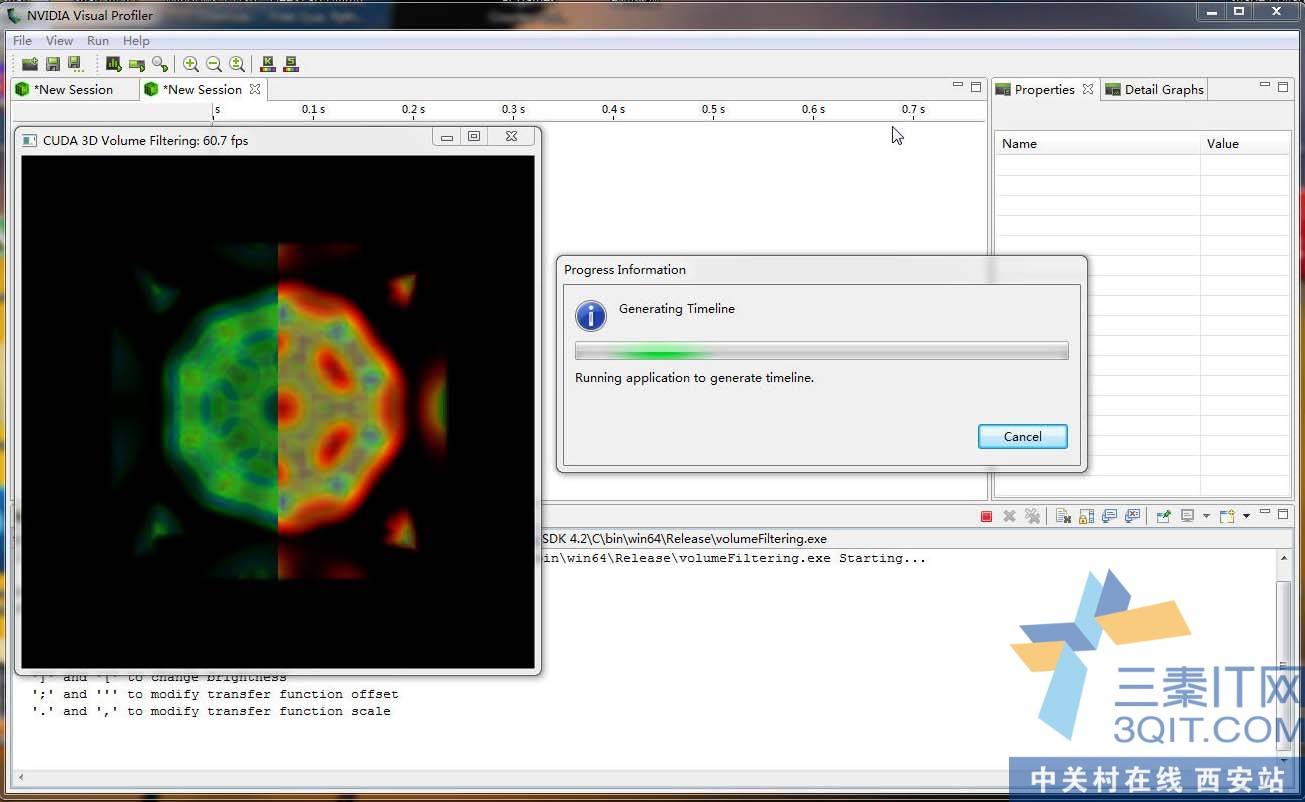
用性能工具来测试CUDA体渲染程序。
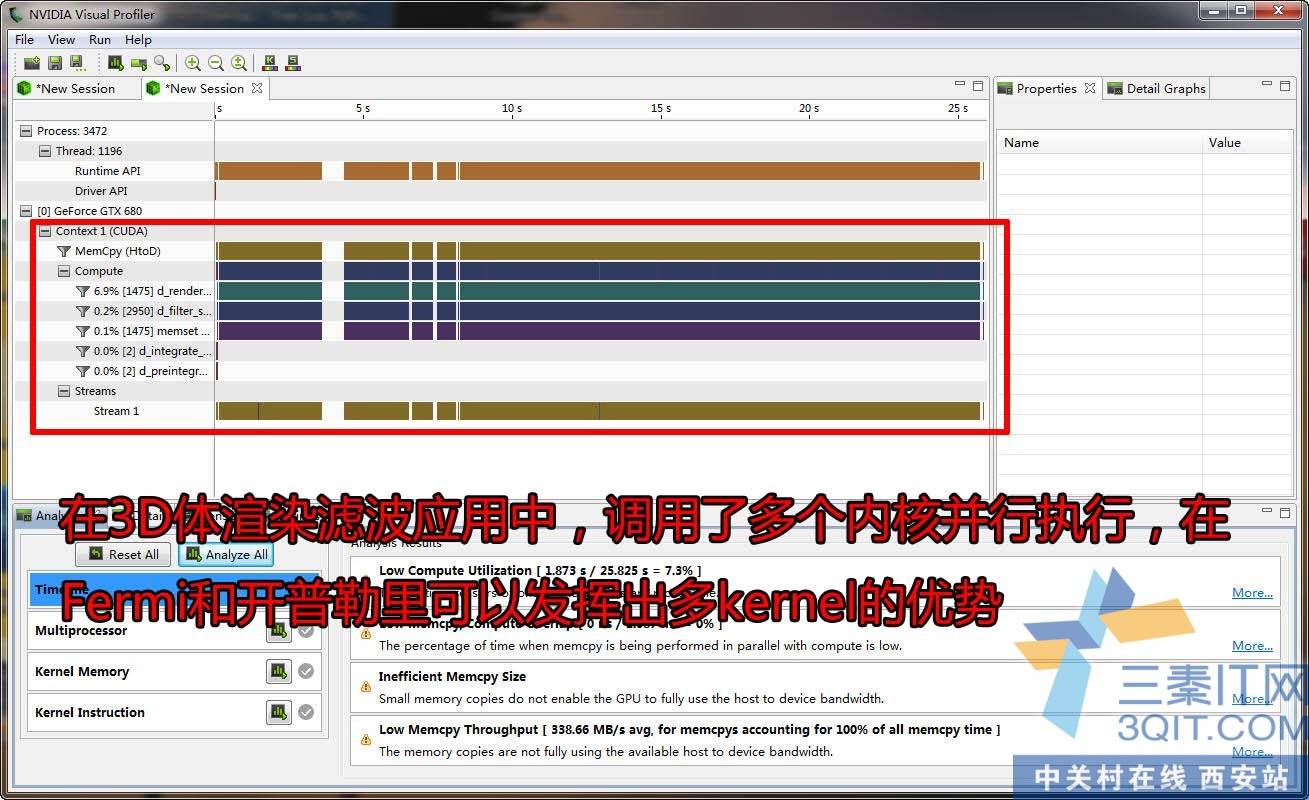
开普勒有多kernel并行运行的优势。
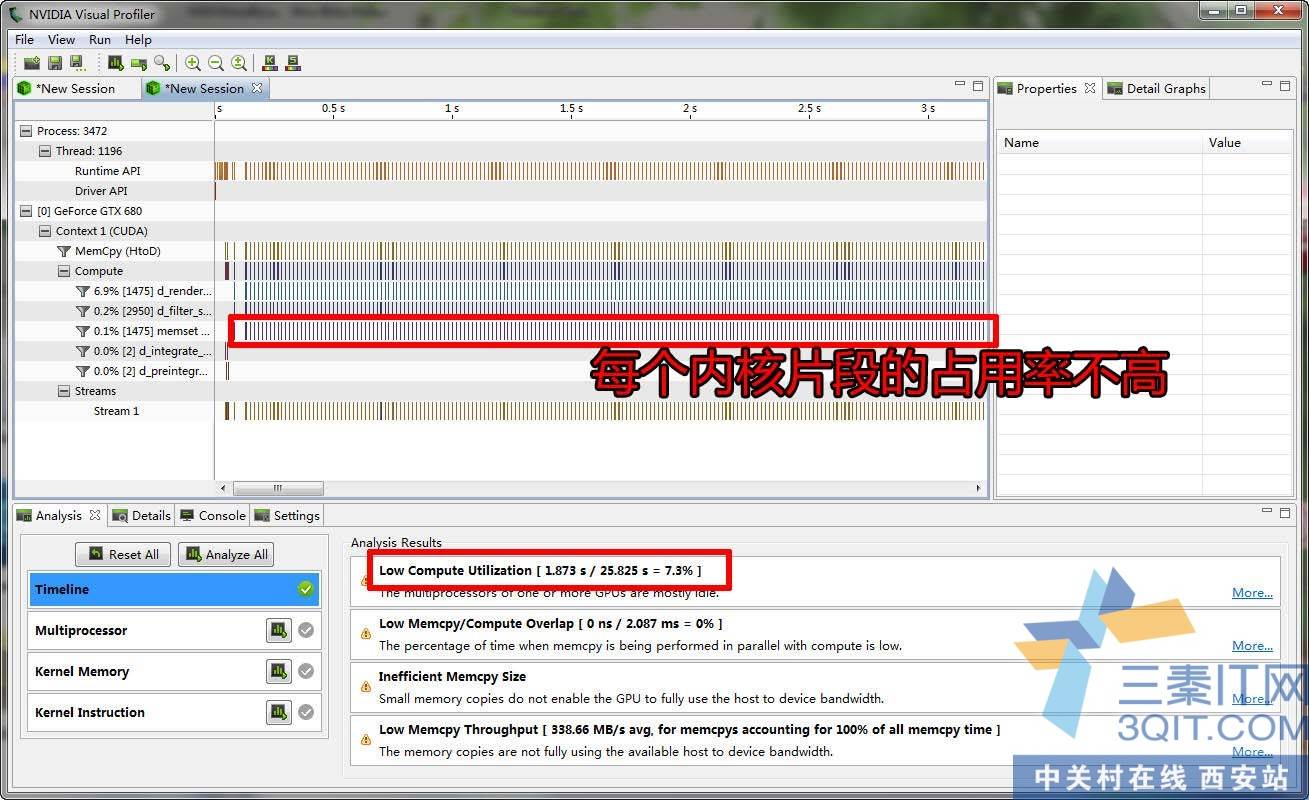
感叹号是表明程序可能有带改进来加强性能。
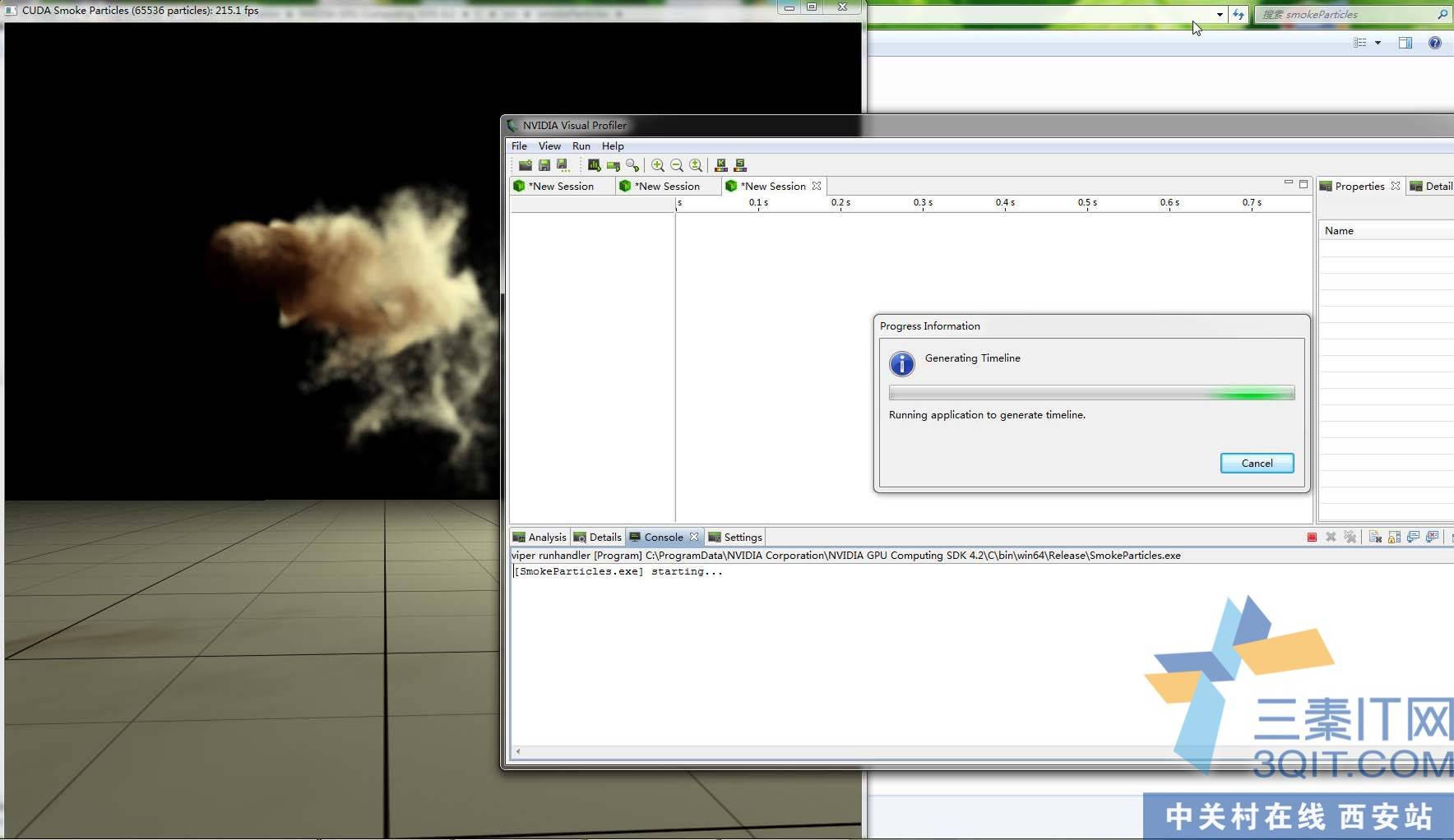
载入粒子模拟仿真。
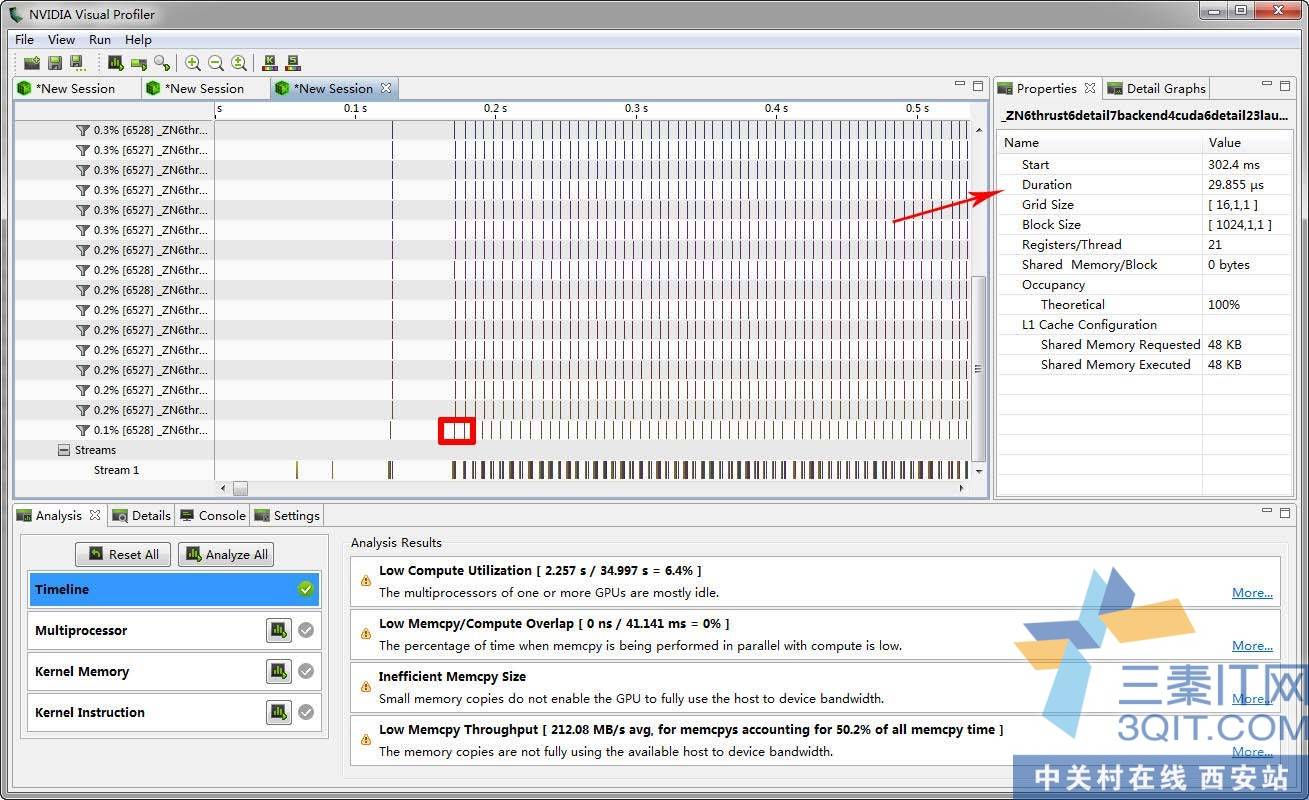
程序性能分析
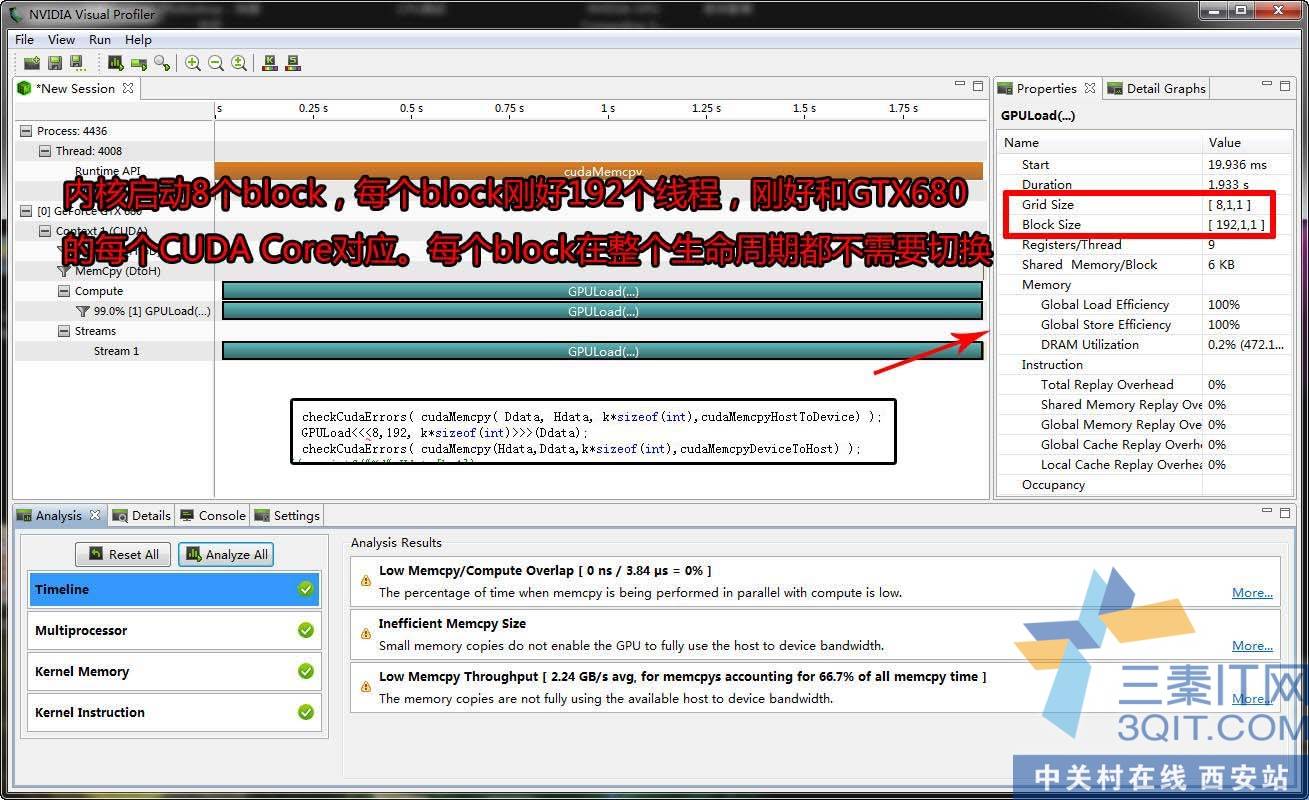
本人写了一段小代码,把GPU所有CUDA核心都运行一个内循环加法,当然,真正的并行程序并没有那么简单。这里是主要是用性能工具来分析GPU ALU的使用率。
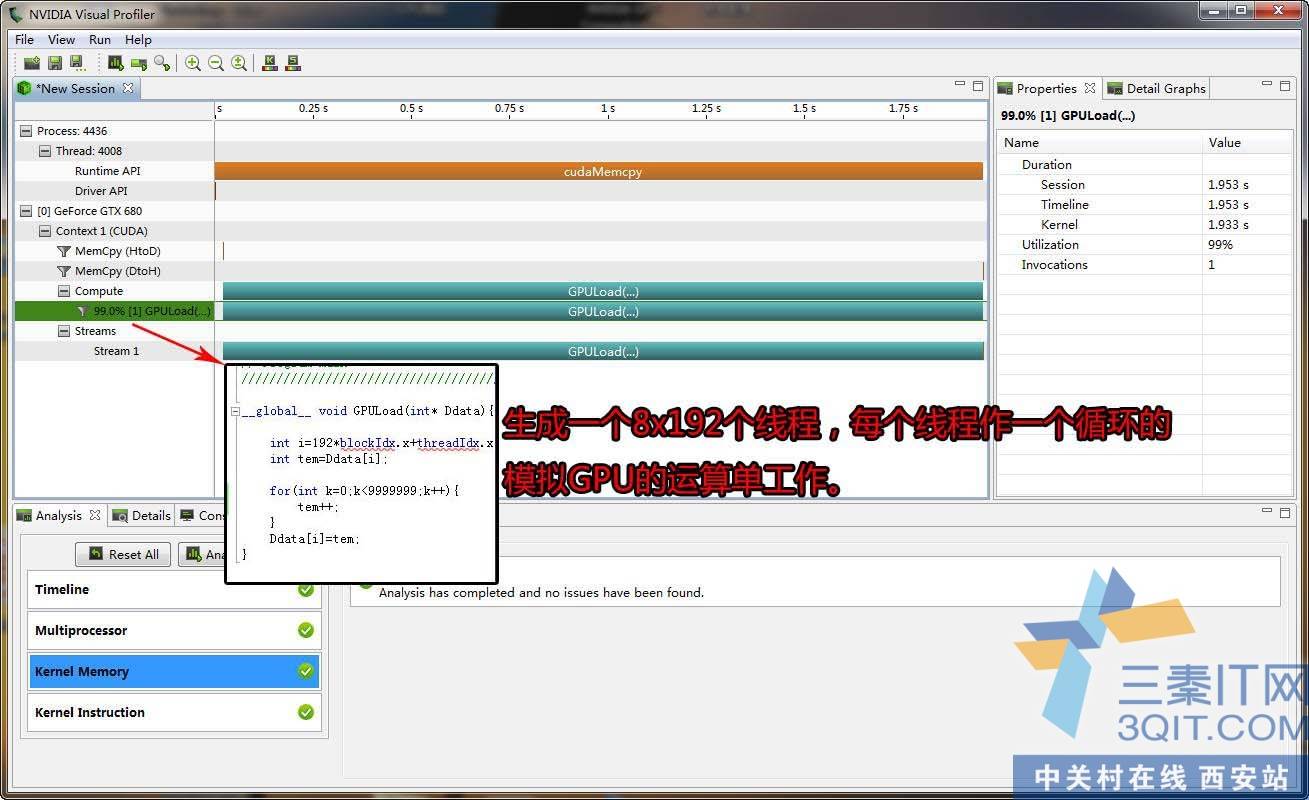
代码主要一一对应地生成1536个线程,每个线程做一个内循环。用来模拟GPU真实的负载工作。另外如果需要,可以调整Grid网格的规格,来增加线程,如果要生成一个百万线程只需要在内核函数输入一个1000000/192=540个BLOCK线程块就可以了。GPU的最大优势是线程实现高速切换,切换的速度是CPU的上千到几千倍。其实CUDA优化就几个点。第一并行算法,另外是适合CUDA的并行算法。然后就是一个具体的调试,SM满载,存储器的blank保持不冲突, 尽量使用寄存器,shared片上缓存。减少LDS单元的试用次数。还有解开小循环,DRAM的合并访问。避免分支结构。流异步执行,指令级的优化,试用吞吐量大的指令,或者有时直接使用SM上的寄存器来加速。尽量使用硬件指令,硬件指令是不用通过软件编译成其他代码,编译后直接就是对应的硬件指令。另外还有就是不分页内存等等。最后技术宅跟我们分享CUDA的一些感觉。CUDA是一个异构的执行体系,就是说CUDA里面你既要写CPU代码,也要内嵌gpu内核代码(GPU)。它是用来发挥两种架构(CPU/GPU)的长处。你认为CPU执行更好的部分,可以在函数用CPU代码实现,你认为某部分交给GPU执行跟好,就可以写成GPU代码。打个比方,某个负责引用需要一个并行度极高的运算和一个串行读很高的复杂运算构成,那就可以先通过PCIE传输数据给GPU并行执行,然后返回给CPU做执行。最终输出结果。另外CUDA的一个用法是CUDA图形相互操作。一个支持physX游戏就是,在图形渲染那和CUDA物理加速相互操作。看到这里,是不是发现自己多CUDA有更加深刻的认识,它不再那么神秘。
三秦IT网的官方微信: 更多资讯请关注:三秦IT网官方微博
更多资讯请关注:三秦IT网官方微博
 性能赶GTX580 耕昇幻影GTX570超频测试
性能赶GTX580 耕昇幻影GTX570超频测试 6款A/N显卡对决 实测蜘蛛侠:破碎维度
6款A/N显卡对决 实测蜘蛛侠:破碎维度 篮球之神乔丹代言 NBA 2K11显卡评测
篮球之神乔丹代言 NBA 2K11显卡评测 灰尘勿扰!拿什么拯救你沙漠中的显卡
灰尘勿扰!拿什么拯救你沙漠中的显卡